How to process XML in Hadoop
May 3, 2018 | By Aditi Hedge

What you’ll learn in this tutorial:
- A primer on XML
- How to process XML using Apache Pig
- How to load an XML file
- How to extract data from tags
- How to use XPath to extract a node
- How to load extracted data into Hive
Digesting varied and vast amounts of data and synthesizing its meaning can be a complicated—but rewarding—undertaking. Using Extensible Markup Language (XML) can help.
What is XML?
XML is a data format popular in many industries, including semiconductor and manufacturing sectors, which captures and records the data from sensors. Processing XML can derive values and provide analytics and data forecasting.
The basic element of XML is tags. An element of information is surrounded by start and end tag. The element name describes the content, whereas the tag describes its relationship with the content. An outermost root element contains all other elements in an XML document. XML supports nested elements and hierarchical structures.
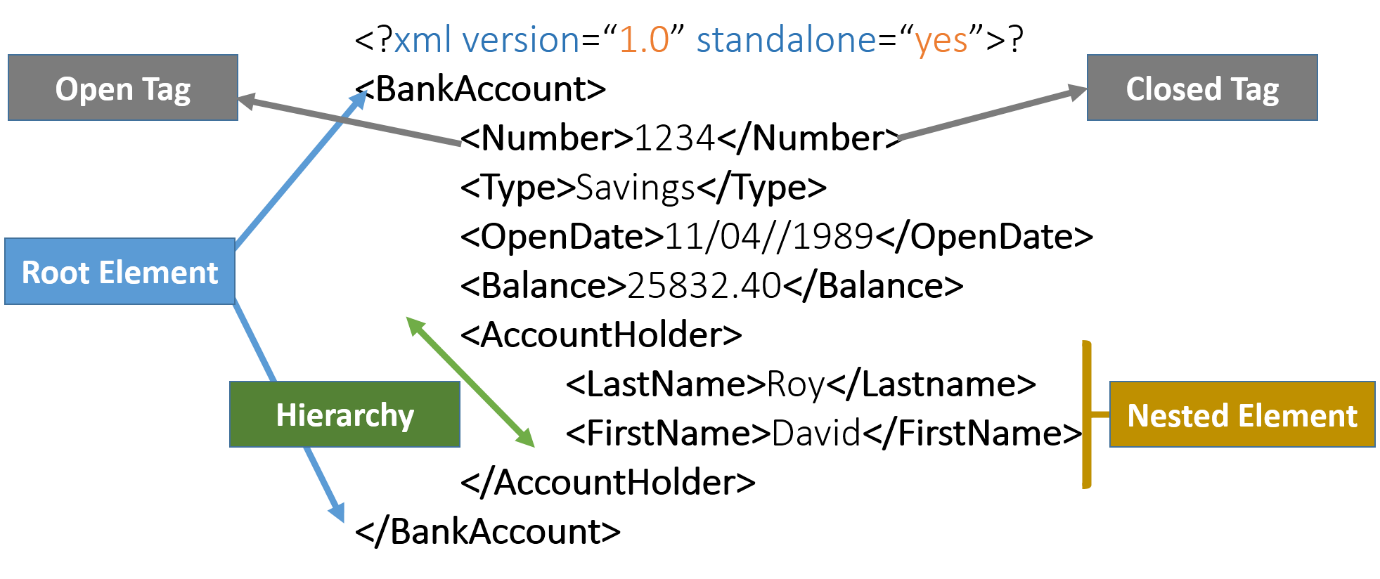
XML is semi-structured. Since the structure of XML is variable by design, we cannot have defined mapping. Thus, to process the XML in Hadoop, you need to know the tags required to extract the data.
Apache Pig is a tool that can be used to analyse XML, and it represents them as data flows. Pig Latin is a scripting language that can do the operations of Extract, Transform, Load (ETL), ad hoc data analysis and iterative processing. The Pig scripts are internally converted to MapReduce jobs. Pig scripts are procedural and implement lazy evaluation, i.e., unless an output is required, the steps aren’t executed.
To process XMLs in Pig, piggybank.jar is essential. This jar contains a UDF called XMLLoader() that will be used to read the XML document.
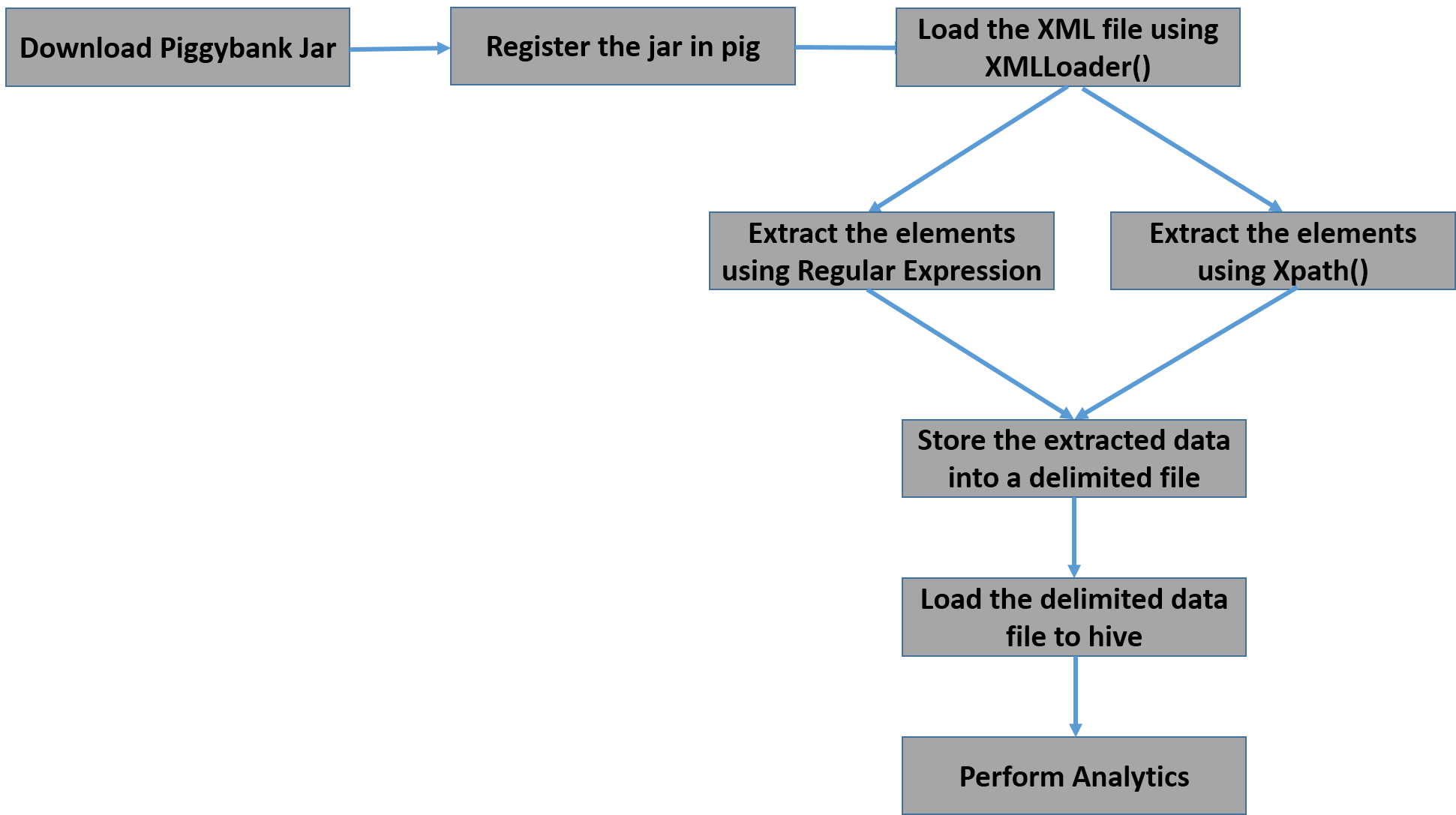
Below is the flow diagram to describe the complete flow from extraction to analysis.
Example
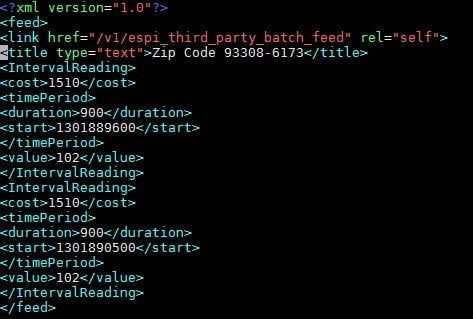
Consider the following XML to be loaded and extracted. The XML contains the cost of the meter reading for the time period.
Download and register Jar
To use Piggybank jar in XML, first download the jar and register the path of the jar in Pig.
![]()
Loading the XML file
Load the document using XMLLoader() into a char array. Specify the parent tag to be extracted. If all the elements are defined under root_element without a parent tag, then the root element will be loaded using the XMLLoader()
In the above example, feed is the root element and the tag to be extracted is food.
If all the elements are defined under root_element without parent tag, then the root element will be loaded using the XMLLoader()

Extracting data from the tags
- To extract data from XML tags in Pig, there are two methods:
- Using regular expressions
- Using XPath
Using regular expressions
Use the regular expressions to extract the data between the tags. Regular expressions can be used to determine simple tags in the document. [Tag <title> in the document]
For nested tags, writing regular expression will be tedious because if any small character is missed in the expression, it will give null output.

Dump the data to see the extracted data.
![]()
![]()
Using XPath
XPath uses path expressions to access a node.
The function for XPath UDF consists of a long string:org.apache.pig.piggybank.evaluation.xml. Thus, you should define a small temporary function name for simplicity and ease of use.
![]()
To access a particular element, start from loading the parent node and navigate to the required tag.
Note that every repeating parent and child nodes become separate rows and columns respectively. In the above file, the tag<IntervalReading> repeats in the file, thus, upon extraction, each tag <IntervalTag> becomes a new row with the tags under it becoming attributes.

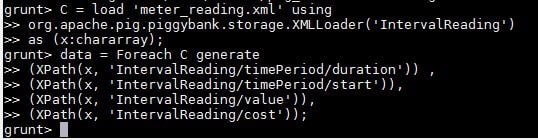
Dump the data to see the extracted data.
![]()
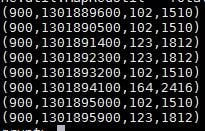
Various transformation can be performed in Pig on the extracted data.
Below is an example to show the conversion of date and calculation of per-unit cost. If multiple files are present, there will be a need to add the key to the data. To add a unique key, load it separately from the XML into a dataset and create a new dataset with required columns.
Below is an example:
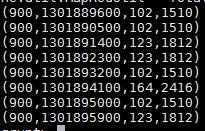
Dump and view the data
![]()
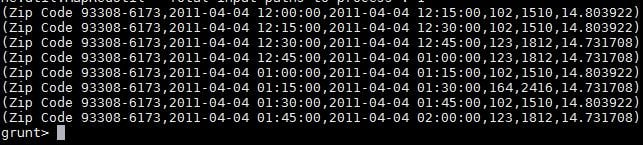
The datasets can be stored in a file with the required delimiter.
![]()
Loading extracted data into Hive
For the first time, create a table in Hive. Load the data into the table created.
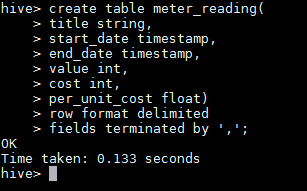

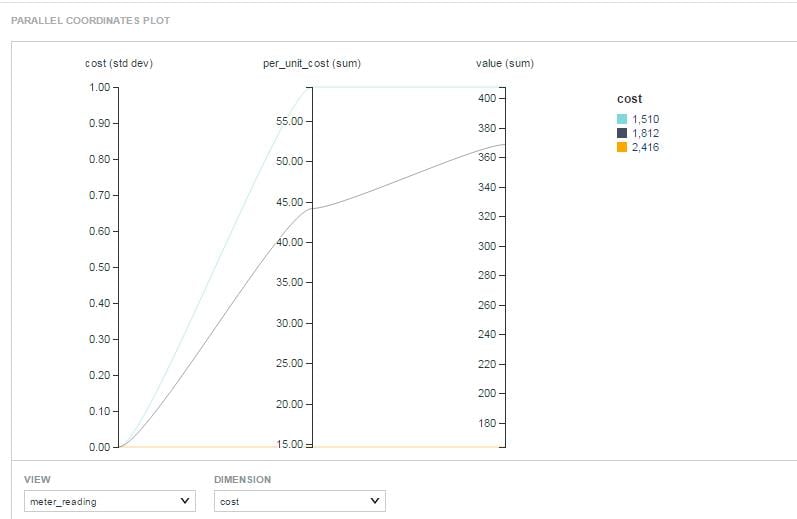
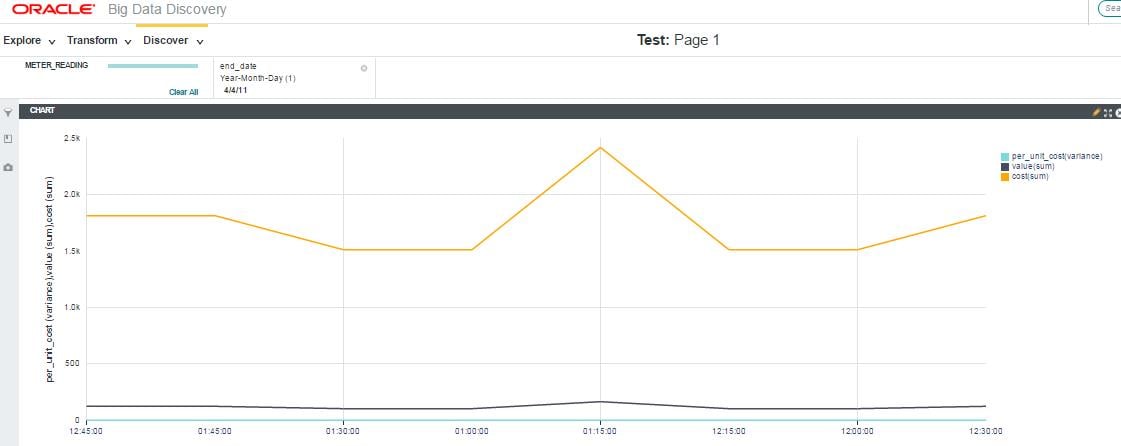
Visualizing the data
The structured data can be visualized in any of the tools like OBIEE, BDD, Tableau or Kibana.