Speed, scale and flexibility with Google Cloud Dataproc and Apache Spark
How to design machine-learning models using Google Cloud Platform
Sept. 3, 2020 | By: Pradipta Dhar

The advent of open-source libraries has been revolutionary for enterprise organizations that regularly design and work on machine-learning models. It has been particularly helpful for both professionals and enthusiasts who have sound knowledge of how machine-learning models work and what characteristics and parameters of the model are best suited to their needs, but who lack the ability to build these models from scratch through translating the math to Python or R code.
However, a challenge that many face in developing machine-learning models is provisioning the infrastructure for the pipeline. In the absence of managed on-demand resources, it becomes a tedious, cumbersome and expensive process to set up and maintain the hardware resources required to build and run a machine-learning model.
Enter: Apache Spark, a distributed framework that can split large-scale workloads into parallel threads by scaling out horizontally based on demand. Since machine-learning models need to be modified or tuned frequently, the distributed nature of the framework helps with speed-to-market and optimizes the critical brain trust—data scientists—by reducing the wait time through the multiple iterations that the training of a model entails.
In this article, we’ll be implementing a machine-learning model on Google Cloud Platform using Google Cloud Dataproc service and Apache Spark. Such a design has significant advantages packaged into one: the speed, scale and flexibility offered by Spark, removal of the overhead of provisioning and maintaining infrastructure beforehand, and optimal cost of maintenance.
What is Apache Spark?
Apache Spark is an open-source distributed execution framework. Spark can be easily integrated into applications using the wide range of libraries it supports for tasks such as machine learning, processing streaming data and SQL.
Being a distributed framework, Spark can process high volumes of data by scaling out to accommodate the demand for resources. The distributed nature of Spark also improves the speed at which it processes data compared to a nondistributed framework. Instructions in Spark can be written in various popular programming languages, such as viz., Java, Python, R, SQL and Scala.
What is Google Cloud Dataproc?
Google Cloud Dataproc is a managed service by Google as part of the Google Cloud Platform. It supports Spark and Hadoop workloads and can be integrated with open-source tools for processing batch and stream data, querying databases, and working with machine-learning models. Dataproc allows us to create, manage and utilize clusters on demand without having to guess requirements beforehand.
Follow along as we create a logistic regression machine-learning model using Apache Spark libraries running on a Google Cloud Dataproc cluster, as can be seen in the diagram below. The dataset being used is a multivariate dataset called “flights.”

Getting started with a Spark interactive shell
1. To begin, we’ll assume that we have a preconfigured Google Cloud Dataproc cluster running on compute engine VMs, without which we cannot proceed with the remaining steps.

2. We start off by launching an SSH session and launching a pyspark session by typing pyspark in the SSH window for the VM.
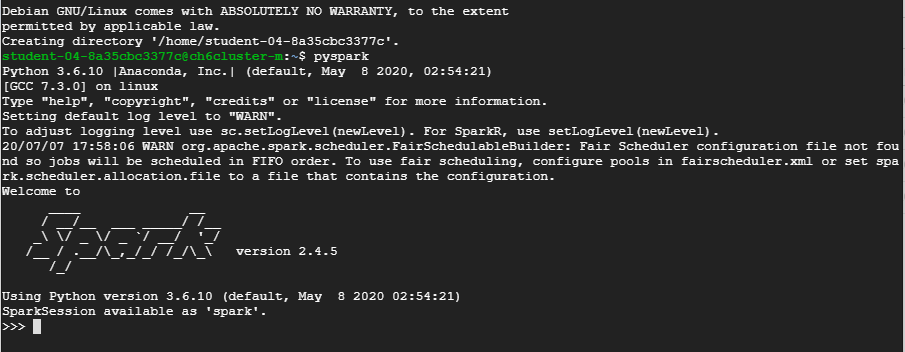
3. Once pyspark is successfully launched, we will be able to see the interactive prompt as seen in the screenshot above. As part of the cluster configuration, Python3 should be deployed and Spark should be configured to use it.
Preparing a Spark training DataFrame
4. Before we proceed with creating the DataFrame, we need to upload our sample dataset (“flights” dataset) in a Google Cloud Storage bucket. We use the Project ID as our bucket name and export the bucket name as an environmental variable using the below command in the SSH window before starting the Spark session:
5. Once we are in the Spark interactive session, we import the libraries required for Logistic Regression by executing the below statements:

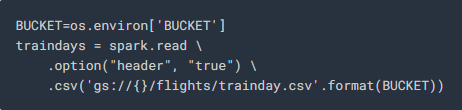
6. Next, we execute the below command to create our training DataFrame by using a file called “traindays.csv”—which contains the dates that contain data that can be used for training our model. In this command, we use the “BUCKET” environment variable we created earlier and use a portion of the “flights” dataset (trainday.csv) for training our model.
The steps to create the prepared csv file like “traindays.csv” for a particular dataset can be accessed from this Qwiklabs tutorial.
The “flights” dataset is divided into two segments, one for training our model and the other for validating and testing our model.
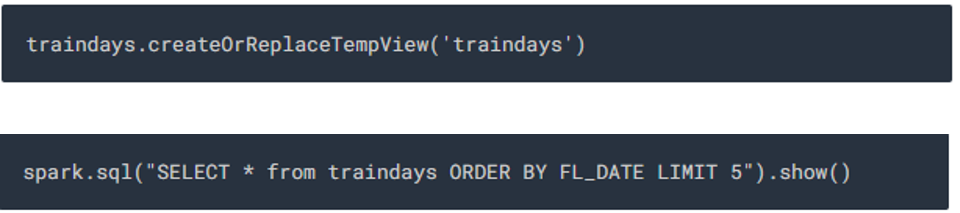
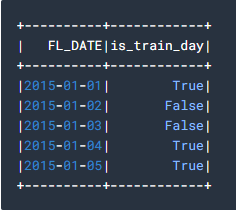
7. Now we will make the training DataFrame into a Spark SQL view for ease of use and query it to view some records in the view by executing the below statements
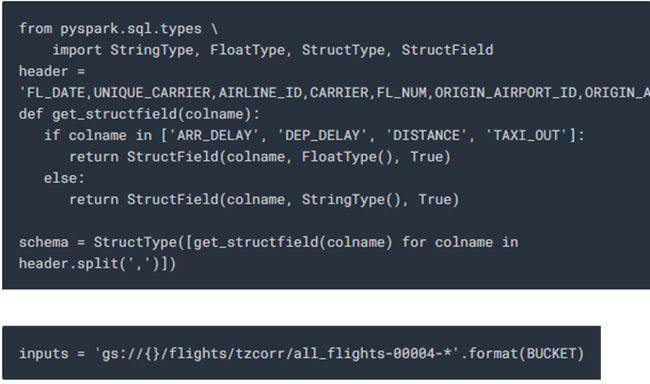
8. After successfully storing the training data in a Spark SQL view, we will create a schema for the “flights” dataset as shown below:
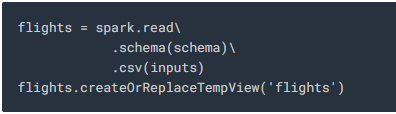
9. Using the schema and input file we created, we read the data into Spark SQL and use the below query to store the data that matches the dates which are valid for training contained in the “traindays” DataFrame.
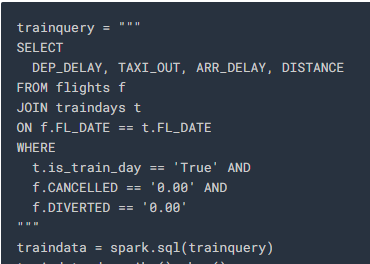
The filters used in the above query help reduce the model error by removing datapoints that do not contribute to training the model in a positive manner and instead add skew to the model, which reduces its efficiency.
Building the logistic regression model
10. The below statement defines the training function for our model:
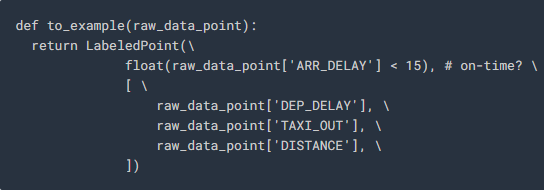
Here, “DEP_DELAY,” “TAXI_OUT” and “DISTANCE” are the features, and “ARR_DELAY” is the label being used to determine if there is a delay in arrival by verifying if the arrival delay is less than 15 minutes.
11. Next, we define our model as shown below by first applying the training function to our training dataset:

Testing our Model
12. To put our model to the test, we will pass it some custom datapoints and observe how it performs.
For our first test case, we pass it the following input parameters:
- Departure delay = 6 minutes
- Taxi out time = 12 minutes
- Travel distance = 594 miles

13. We can then test our model by increasing the departure delay to 36 minutes, and we see that the output is 0, which means that the flight will be delayed.
Our model here is a binary logistic regression, which classifies our model output into two possible classes using a predefined threshold.
We can alter this behavior to observe the actual probabilities of on-time/delayed arrival by clearing the thresholds or even altering the thresholds to suit our needs.
Apache Spark and Dataproc enable machine-learning models at speed
The advantages of using Spark and Dataproc in Google Cloud Platform are obvious when we view it in comparison to accomplishing the task without the use of the Spark libraries and on-demand resources in a cloud environment.
By the end of this example, we’ve built a logistic regression model, provisioned resources for our model and were able to use our model to predict actual outputs all in the blink of an eye. If we were to attempt the same tasks without the use of libraries, provision resources and infrastructure on our own without access to Google Cloud’s on-demand resources, it would not have been half as convenient. It would require hours of planning and tedious conversion of the math behind the machine-learning model to code.
One thing to be cautious of when it comes to using compute engine VMs: They should not be left running when they are idle, as this can lead to unexpectedly high charges for resources being run even when there is no utilization. Learn more about how to prevent unexpectedly high bills and proper billing monitoring.
The spark statements and screenshots above are part of Google’s Machine Learning with Spark on Google Cloud Dataproc lab.
Pradipta Dhar is a principal software engineer at TEKsystems with extensive expertise in machine learning and big data.